Transformers
과거 주류 모델
Sequence-to-Sequence (Encoder Decoder Model)
With Recurrent or Convolutional Model
= 이전 단어가 다음 단어에 영향을 줌

Activation Functions
: 모델에 비선형성(non-linearity)을 추가
선형성(linearity) : linear transformation (행렬 덧셈과 곱셈)
후에도 선형성을 유지

linearity의 단점 : deep neural network 구축해도 single neural network로 표현
선형성 단점은
레이어 하나를 통과한 결과
z를 다 통과해보니까 결국엔 하나의 single neural network로 표현됨
비선형성 (non-linearity) : linear transformation (행렬 덧셈과 곱셈) 후에 선형성을 유지하지 못함

학습을 시킬때 순차적으로 곱해가다가 error가 나오는데
Error 값을 통해 back propagation을 하게 된다
실무하면서 ~
Transformer 부모클래스로 받아오고
자식클래스로 일부 수정할 부분만 수정해주는 경우도 있음
RNN, CNN 쓸때 단점 :
Fixed-size-vector -> encoder의 입력값 정보를 fixed-sized- 담아야함
Trnasformer : Attention-only
Trnasformer 아키텍처
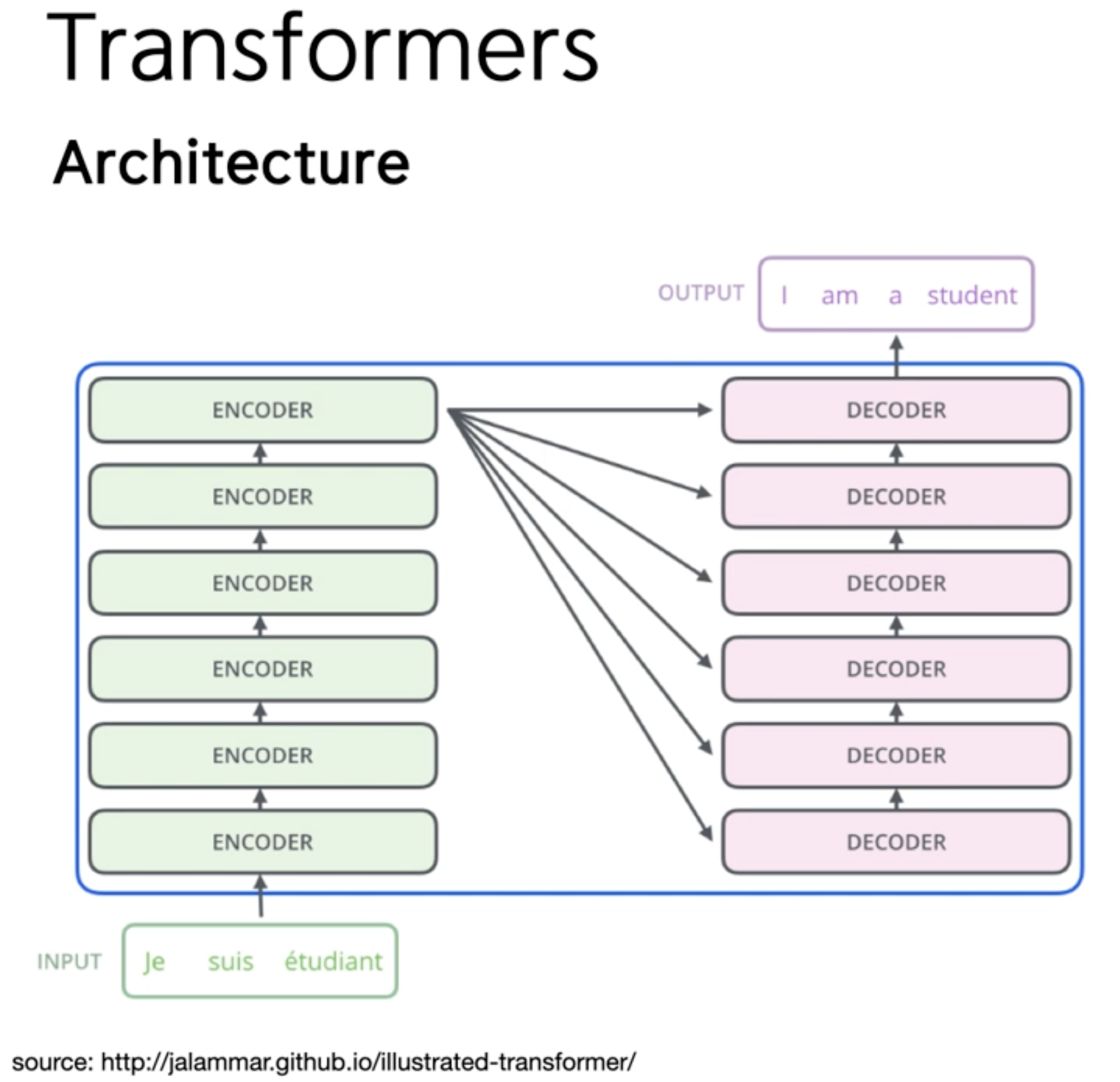
장점
- 성능 향상
- 병렬 처리 가능
- Batch-processing
- 학습 속도 감소

<RNN>
Training #1 : A -> B -> C
Training #2 : X -> Y -> Z
하나의 값을 보고 error를 업데이트 하고 최소화함
학습데이터를 한번에 몇개를 보고 학습을 할래 정해준다 —> batch
앞에 것이 끝날때까지 기다려야함
<Transformer>
Training #1 : A, B, C
Training #2 : X, Y, Z
한번에 매트릭스와 연산을 하게 된다 (병렬 처리가 가능해서 한번에 처리할 수 있다)
Transformers Arichtecture
Input Embedding
Positional encoding = “순서” 정보를 포함
그림x
홀수에 대한 것은 sine 함수
짝수인 것은 cos 함수
Encoder (N=6)
2-1. Multi-head self-attention
2-2. Position-wise fully connected feed-forward network
Residual connection + (layer) normalization
bert도 크기마다 모두 다르다
Attention-head 개수나
워드 벡터 차원에 따라서 bert 모델이 달라질 수 있다.
Bert-base : encoder 6개 쌓았다.
Bert-large 등
Transformers Architecture
Self-attentions

1)
self-attention은 query, key, value 3가지만 알고 있자.

W 값을 계속 바꿔준다
- Score 계산 (논문에서 dk = 64)
Query, key, value를 어떻게 쓸건데?
RNN은 히든층에 모든 정보를 담아야 되는 부담이 있었음
내가 관련된, 보고 싶은 정보만을 저장한다
단어가 2개라면 softmax 2개를 만든다
클래스 별로 비교를 하고 싶을때 softmax를 사용하게 된다
Self-attention output 계산 : score * value
그림
Self-attention (matrix)
그림
토큰1과 토큰2의 연관성을 보게 된다
Multi-head self-attention ( matrix)
Key, Query, Value matrix를 head 개수만큼 (# heads=8) 늘리자!
—> 토큰간의 관계를 여러 차원에서 볼 수 있음
BertViz Interactive Tutorial
Bert 학습 -> 어떤 문장 입력 -> 트랜스포머 안에서 레이어가 12개 (bert-large 레이어개수 12개)
Layer 마다 어텐션, 어텐션 헤드가 나오게 된다
Cat 이 the와 관련이 있는 것을 학습하는 것도 있고 (파란색 - 관사 학습)
Sat 다음에 on, lay 다음에 on 이 온다는 것을 학습하였음 (자주색- 전치사 학습)
RNN은 이전 학습이 끝나야 다음 학습을 할 수 있는데
모든 토큰들이 매트릭스와 곱해져서 굉장히 학습 시간이 빨라진다
Multi-head self-attention (matrix)
Cancat은 그냥 다 붙여주는 것
근처 값을 더한다 곱해주는 것 ??
W는 계속 업데이트 되는 값
어떤 인코더의 출력이 다른 인코더의 입력이 될 수 있기 때문에
인풋 차원이 512라면 컬럼이 512 차원과 곱해서
차원을 마지막으로 곱해서 계산함
인풋 -> 임베딩 -> 토큰으로 만들지 않고 쌓아서 매트릭스로 만듬 ->
각각 토큰마다 키와 쿼리를 곱해주고 dk = 8이면 value값을 만들고
softmax로 확률값을 만들고 특정 토큰과 관련이 많은 것들은 살려두고
토큰과 관련이 적은 것은 제거
이런 절차를 헤드 하나에서 진행함
모든 헤드가 이런 절차를 거침
W0 원하는 사이즈로 만들어준다
인코더의 아웃풋이 출력된다
Add & Norm = residual connection + (layer) normalization
Transformers Architecture
Residual Connection
Deep Neural Network 의 문제점
—> “Vanishing gradient problem” 해소
단순히 output만 쓰는게 아니라 기존 input 값을 더해주었다.
인코더 값도 많은데 어텐션, 피드포워드 값을 원래 기존 값을 더해서 반영해주었다.
Layer Normalization
값이 너무 크거나 너무 작으면 안된다 .
값이 정규분포상에서의 값을 취하고 있어야 학습이 잘된다.
Residual + Layer Normalization
Position-wise fully connected feed-forward network
- forward는 예측값을 만들어가는것
- 순차적으로 곱셈을 해나가는 것 : feed-forward
- 모든 레이어에서 행렬곱 : fully-connected
Normalization 을 통해 결과값 출력이 나오게 된다.
오늘은 skip-connection 등등
내일 인코더, 디코더 모두 구현 (트랜스포머 베이스 모델)
- 다 어떻게 동작하는지 알았음
'자연어 처리' 카테고리의 다른 글
| GPT2를 활용한 한국어 언어생성 모델-자연어처리_23-08-21,22 (0) | 2023.08.22 |
|---|---|
| JinCoding 실무형 NLP Course 5강 : Transfomer 실습 - 23-08-20 (0) | 2023.08.20 |
| 자연어처리_챗봇_23-08-16 (0) | 2023.08.16 |
| 자연어처리_챗봇_23-08-14 (0) | 2023.08.14 |
| 자연어처리_챗봇_23-08-11 (0) | 2023.08.14 |


