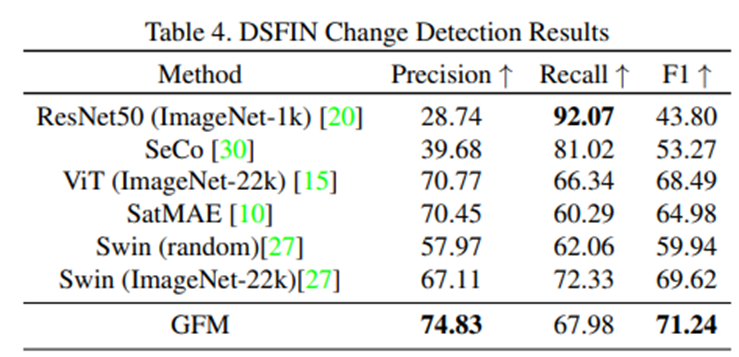

Most recently, SatMAE [10] explores the use of masked image modeling to train a large ViT model. This work is similar in some respect to ours, as we also train a transformer model with an MIM objective. However, we find that SatMAE often does not perform better than the off-the-shelf ImageNet-22k pretrained ViT (Section 4). This indicates both the difficulty of building strong geospatial pretrained models from scratch and highlights the potential usefulness of leveraging continual pretraining instead, as we investigate in this work.
In general, the goal is to learn from data in a self-supervised manner by asking the model to generate pixel values for intentionally-withheld regions in an image.
가장 최근에는 SatMAE[10]에서 마스크 이미지 모델링을 사용하여 대규모 ViT 모델을 훈련하는 방법을 살펴봅니다. 이 작업은 MIM 목표를 가진 트랜스포머 모델도 훈련하기 때문에 우리와 비슷한 점이 있습니다. 그러나 SatMAE는 종종 기성 ImageNet-22k 사전 훈련된 ViT(섹션 4)보다 성능이 뛰어나지 않다는 것을 발견했습니다. 이는 강력한 지리 공간 사전 훈련 모델을 처음부터 구축하는 것이 어렵다는 것을 나타내며, 이 작업에서 조사하는 것처럼 대신 지속적인 사전 훈련을 활용하는 잠재적인 유용성을 강조합니다.
일반적으로 목표는 모델에게 이미지에서 의도적으로 보류된 영역에 대한 픽셀 값을 생성하도록 요청하여 self-supervised 방식으로 데이터에서 학습하는 것입니다.
아래는 ResNet50과 ViT, SatMAE 방식에 대해 모델 성능 평가한 결과이다.