JinCoding 실무형 NLP Course 2강: 컴퓨터가 언어를 이해하는 방법
스터디 기록일지^^
- 날짜/시간 : 23년 08월 06일 / 오후 7시
[2] 컴퓨터는 언어를 어떻게 이해할까?
Text Preprocessing
- Feature extraction (ENG)
Lemmatication : lemma (단어 기본형 )
Stemming : stem (어간) / 접두사 , 접미사 제거
Use Case ?
- 사전을 차원(사이즈)를 감소하기 위해
- 검색 시스템에서 의미를 빠르게 그리고 효율적으로 추출하기 위해
- Feature extraction(영어)
Use Case ?
- 특정 품사 단어를 가져와서 처리
- Ex) 명사 단어만 가져와서 word cloud 그리기
- Feature extraction (KOR)
형태소 분석 .!!
형태소란?
- 의미를 가지는 가장 작은 단위
- (예시) 가방에 들어가신다 -> 가방/NNG + 에/JKM + 들어가/VV + 시/EPM + ㄴ다/EFN
spaCy 파이썬 패키지 소개
- 한국어 사전을 가져와서 사용함
- Multi lingual
- 이단어가 주어다 이단어가 동사다 = dependency parser
- tagger는 품사를 태깅해주는것
Text Preprocessing
- Feature extraction (ALL)
- Preprocessing pipeline package
- Tagger
- Paser
- Ner (개체명인식) -> 문서를 이해하고 엔티티를 뽑을 때 사용 (사람 이름을 뽑고 싶어)

- Text cleaning
Regular Expression
- pattern
- string (text)
- flag
- re.IGNORECASE : 대소문자 구분하지 않음
- re.MULTILINE : 라인별로 찾을 수 있음
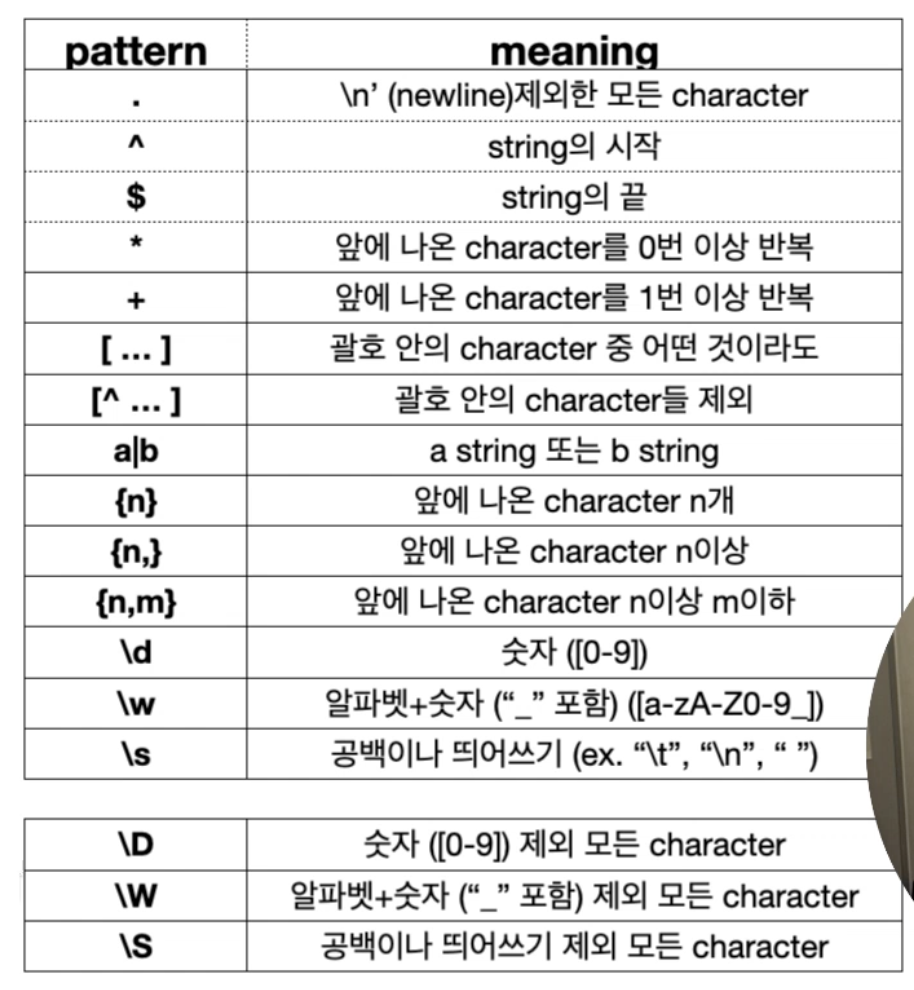
- Text cleaning
- Functions
- search() : string 에서 첫번쨰로 찾은 pattern을 match 객체로 반환
- match() : pattern이 string의 0번째 위치에 있으면 match
- sub() : pattern을 특정 텍스트로 교체
[2] 컴퓨터는 언어를 어떻게 이해할까 ?
- Tokenizer
- Whitespace Tokenizer
- Word Tokenizer
- Character Tokenizer
문제: Out-of-Vocabulary (OOV)
Ex. 신조어 ?!
- Large Language Model
단어 -> 모델 -> Embedding
Vocab
GPT3: 50,257 tokens
BERT: 30,522 tokens
token을 어떻게 만들까?
기법: tokenizer
Tokenizer
Large Language Model -> Subword Tokenizer
- BPE (Byte Pair Encoding)
“ 자주 등장하는 character 쌍(pair)을 병합”
“Low lower newest wideset”
-> character 단위로
-> 빈도가 높은 pair를 병합
“ lo w lo w e r n e w e s t w I d e s e t”
-> vocab_size 도달할때까지 병합함
- WordPiece[BERT tokenizer]
“Likehood가 높은 character 쌍(pair)을 병합”
Likehood란 ??
"우리가 빅데이터를 보고나서 우리가 가지고 있는 모델이 빅데이터와 유사하도록 모델을 계속 업데이트하는 것 "
# a = a 빈도
# b = b 빈도
# ab = ab pair 빈도
Character 단위로 + prefix (##) 추가
“Low lower newst widest”
“l##o##wl##o##w##e##rn##e##…..”
pip install transformers 를 설치해야 Tokenizer를 쓸 수 있다
Special Tokens
[CLS] : NSP 예측 -> classification task
[SEP] : 문장간 구분자
[UNK] : vocab에 없는 토큰 —> unknown 으로 바꾼다(bert가 모르는 것은 모두 unknown으로 표시)
교수님 요즘 고민
- 사람들이 어떻게 바로 쉽게 접근해서 AI를 쉽게 접근할 수 있을까
- 랭귀지 모델이 어떻게 바뀔까 트래킹 하기
- 코드를 짜는걸 좋아함 서비스를 구축하는게 재밌음
- PPT로 정리하고 전자책을 정리해보는 시간도 가져보면 좋다
- chatgpt를 통한 자동 블로그 포스팅