DOFA의 Positional Encoding은 어떻게 되어있을까 (구조적 관점)
어제 나온 이슈와 관련이 있는 것 같아서 연구를 해보려고 한다.
RuntimeError: Error(s) in loading state_dict for MaskedAutoencoderViT:
size mismatch for pos_embed: copying a param with shape torch.Size([1, 197, 768]) from checkpoint, the shape in current model is torch.Size([1, 5, 768]).
size mismatch for decoder_pos_embed: copying a param with shape torch.Size([1, 197, 512]) from checkpoint, the shape in current model is torch.Size([1, 5, 512]).
==== ==== ==== ==== ==== ==== ==== ==== ==== ==== ====
pos_embed와 decoder_pos_embed 사이즈가 틀려서 발생하는 문제.
에러 내용을 정리하면,
체크포인트의 pos_embed는 [1, 197, 768] 사이즈를 가짐
decoder_pos_embed는 [1, 197, 512] 사이즈를 가짐
변화탐지 디코더 모델의 pos_embed는 [1, 5, 768] 사이즈를 가짐
decoder_pos_embed는 [1, 5, 512] 사이즈를 가짐
[문제]
추가로,
(문제1) Dynamic One-For-All (DOFA) model의 pos_embed 197 사이즈는 무엇인지,
(해결1) 주어진 positional encoding의 크기 (1, 197, 768)은 Transformer 기반 모델(예: ViT)에서 자주 사용되는 크기입니다. 여기서:
- 1: 배치 크기 (batch size)
- 197: 패치 수 (예: 14x14 패치 + 1 [CLS] 토큰)
- 768: 임베딩 차원 크기
이 데이터를 시각화하기 위해 배치 차원을 제거하고, 197 개의 패치를 올바르게 다룰 수 있도록 수정해야 합니다.
수정된 코드는 배치 차원을 제거하고, CLS 토큰을 처리하여 나머지 패치들을 정사각형 형태로 시각화합니다.
CLS 토큰이 포함된 경우 이를 제외한 후 나머지 패치들만 시각화에 사용합니다.
(문제2) 변화탐지 디코더 모델의 pos_embed 사이즈를 왜 5로 설정되어있는가 고민.
(문제3) Dynamic One-For-All (DOFA) model의 decoder_pos_embed을 512로 하고 있었음
models_base_ofa_mae.py 파일에서 아래 코드 확인하였음.
[증거1]
self.pos_embed = nn.Parameter(torch.zeros(1, self.num_patches + 1, embed_dim), requires_grad=False) # fixed sin-cos embedding
분석 1: 값이 0 근처에 집중된 이유
초기화 값이 torch.zeros: models_base_ofa_mae.py에서 확인된 코드에 따르면, positional encoding은 torch.zeros로 초기화됩니다. 따라서, 초기 상태에서는 모든 값이 0입니다.
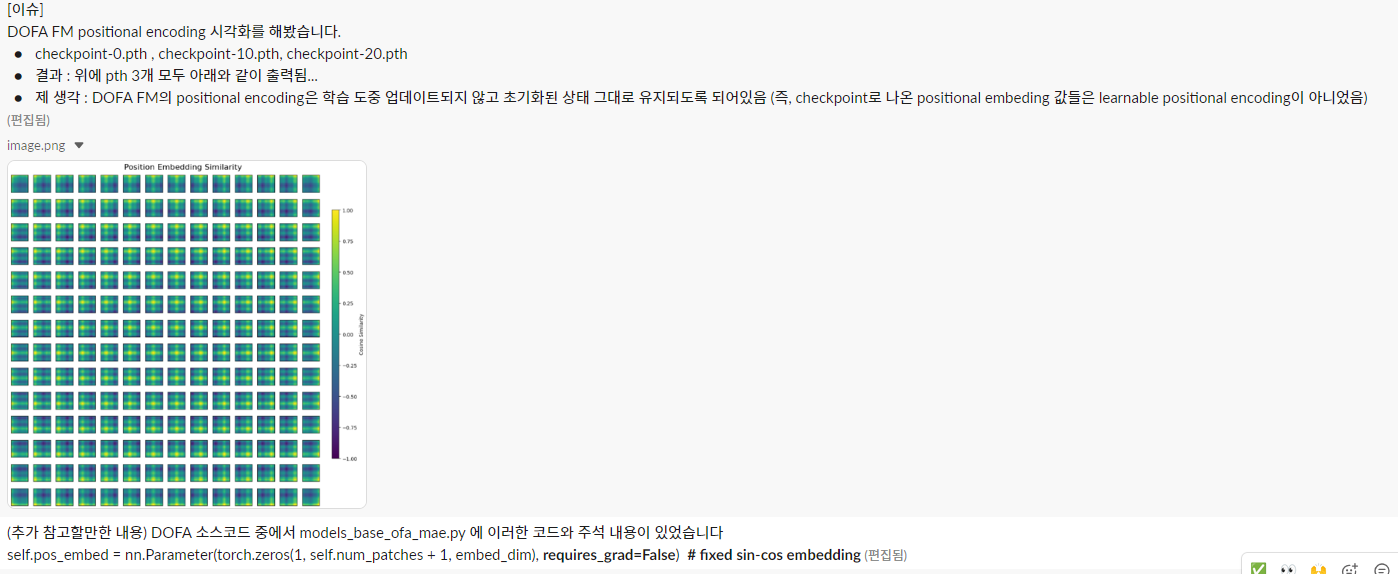
requires_grad=False: 이 설정은 positional encoding이 학습되지 않는다는 것을 명확히 나타냅니다. 즉, 모델 학습 중 positional encoding 값은 고정됩니다. 따라서 사전학습(Epoch 0, 10, 20) 동안 positional encoding 값이 동일하게 나오는 것이 정상적인 동작입니다.
코드에 따르면 positional encoding은 requires_grad=False로 인해 학습되지 않습니다. 따라서 positional encoding은 학습 도중 업데이트되지 않고 초기화된 상태 그대로 유지됩니다.
분석 2: 모델에 미치는 영향
Positional encoding 값이 0 근처로 고정된 상태라면, 모델의 성능에 다음과 같은 영향이 있을 수 있습니다:
- 위치 정보가 반영되지 않음: Positional encoding의 역할은 입력 토큰이나 패치의 상대적 위치 정보를 모델에 제공하는 것입니다. 값이 0으로 유지되면, 모델이 위치 정보를 활용하지 못하고 입력 데이터만으로 학습을 진행하게 됩니다.
- 성능 저하 가능성: 특히, Transformer 구조는 위치 정보를 명시적으로 추가하지 않으면, 순서와 관계없는 self-attention 메커니즘에 의해 위치 정보를 학습하기 어렵습니다. 이는 모델의 성능 저하로 이어질 수 있습니다.
아래 그래프의 결과를 보면, positional encoding 값의 분포가 0에 매우 집중되어 있다는 것을 알 수 있습니다. 이는 positional encoding 값이 학습되지 않고 초기화된 값에 머물러 있음을 강하게 시사합니다.
[증거2]
def initialize_weights(self):
# initialization
# initialize (and freeze) pos_embed by sin-cos embedding
pos_embed = get_2d_sincos_pos_embed(self.pos_embed.shape[-1], int(self.num_patches**.5), cls_token=True)
1) Sin-Cos Positional Encoding 초기화
- get_2d_sincos_pos_embed 함수가 사용되어 positional encoding을 2D Sinusoidal 방식으로 초기화합니다.
- self.pos_embed가 Sin-Cos 값을 가지도록 설정됩니다.
2) cls_token=True
- CLS 토큰에 해당하는 positional encoding 값도 함께 초기화됩니다.
- 이는 일반적으로 Transformer 구조에서 global feature aggregation을 위해 사용하는 특수한 위치값입니다.
3) Freeze (동결)
주석에 따르면, Sin-Cos embedding은 초기화된 후 freeze(학습되지 않음) 상태로 유지됩니다.